Kafka - Beginners
This post is based on this kafka course [Kafka for Beginners]. Here is exposed some concepts to help the first understanding and a fast consult.
Here are simple examples of using Kafka for the first time. To have some practices you can read: [Conduktor - Tutorial]; [Conduktor - get-started]; [Apache Kafka - quickstart]. Here [Upstash - Kafka playground] is a platform where you can create your playground for your tests.
Start kafka locally
$ zookeeper-server-start /opt/homebrew/Cellar/kafka/3.6.1/libexec/config/zookeeper.properties
$ kafka-server-start /opt/homebrew/Cellar/kafka/3.6.1/libexec/config/server.propertiesIntroduction
Here is the scenario where kafka can fit:
- Problem: Integration among multiple sources and targets
- Difficulties: Protocol, Data format, data schema and evolution
- Solution: Kafka decoupling data stream and systems. Kafka works as a data integration layer.
- High performance, scalable, elastic, distributed, resilient, fault tolerant
- Used as a transportation machanism
- Capabilities: publish/subscribe streams of events; store streams of events; process streams of events
Kafka is an open-source distributed event streaming platform consisting of servers and clients. Event streaming is the practice of capturing data in real-time from event sources. Apache Kafka is used primarily to build real-time data streaming pipelines. [Conduktor][Apache Kafka]
Fundamentals
The fundamentals concepts was collected from [1][2]
Event
Fact that happened in the business and recorded (read/write) in Kafka. An event has key, value (message content), timestamp, metadata, compression type, headers, partition and offset.
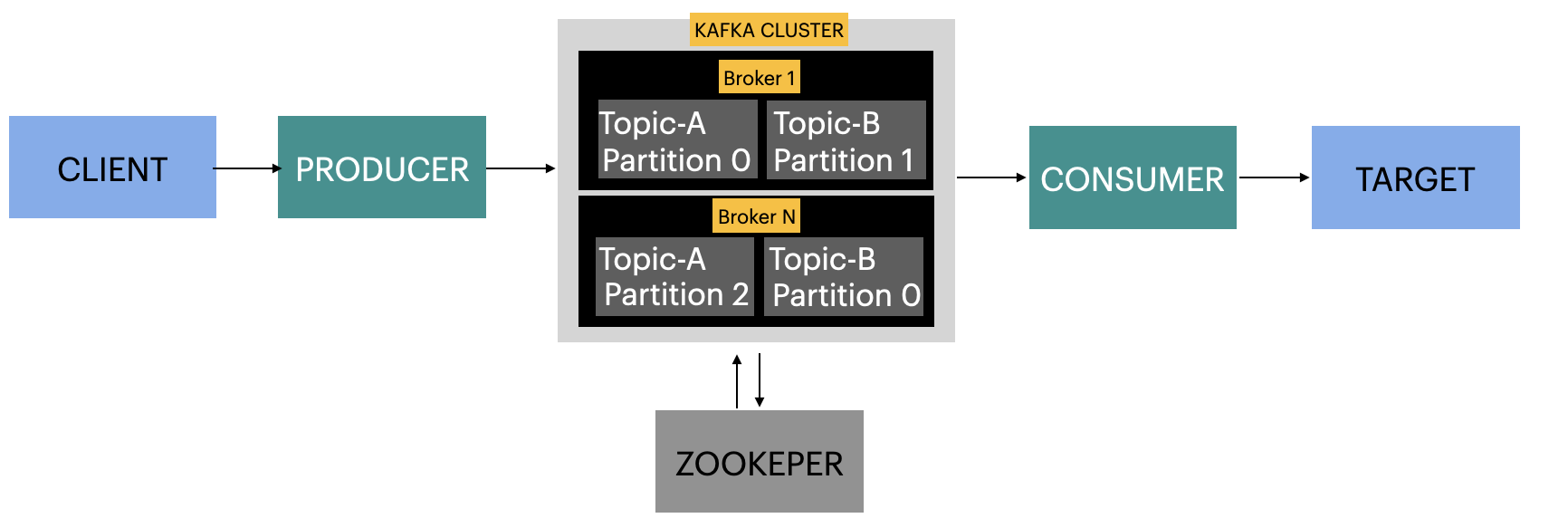
Broker
- It is a kafka server
- A set of these servers form the storage layer
- Each broker is identified with its ID
Kafka cluster
- It is a set of brokers (servers) working together
- Data is distributed across all brokers
- A client can connect to any broker in the cluster
- Every broker in the cluster has information (metadata) about all the other brokers, topics and partition
- Bootstrap Server: the broker in the cluster
- The metadata returned from bootstrap server to the clinent make possible them to know which broker to connect
Kafka Connect
Import and export data as event streams to integrate Kafka with your existing systems and other Kafka clusters [Connectors]
Topics
- Store the events in the broker like a directory
- A topic is identidied by the name [Convention]
- A kafka cluster can have many topics
- It acepts any kind of message format
- You cannot query topics
- Kafka topics are immutable. It's not possible change or delete data in kafka. The message is discarted by setting the configuration per-topic
- It is different of RabbitMQ and ActiveMQ that use queues which scale to millions of consumers and allow delete messages once processed
Partitions:
- A topic can be split in particions located on different Kafka brokers
- Each topic-partition receives its own sub-directory with the associated name of the topic
- Each broker contains a topic partition
- Offset: incremental id given to messages inside the partition as it is written into a partition
- It represent the position of a message within a Kafka Partition
- Messages within partition are ordered by the offset
- Offset of different partitions have no relation
- No garantee of order among the partitions
- Offsets are commited as soon as messages are received (consumed)
- Offsets are not re-used
- A data is assigned randomly to a partition (round robin) unless a key is provided (hash strategy)
- Message with the same key goes to the same partition
- Each partition can have multiple reader
- Leader of partition: only one broker can be a leader for a partition
- Kafka partitionerM: logic to decide which partition to send a record
Topic replication factor
- Copy of the data across the brokers
- Specified at topic creation time
- It is done at the level of topic-partitions
- A replication factor of 1 means no replication (development purposes)
- Topics should have replication factor > 1 (localhost is only 1 but it is development purpose)
- Common replication factor: 3 (good balance between broker loss and replication overhead)
- In-Sync Replicas (ISR): replica is up to date with the leader broker for a partition
// If try to create a topic that not exist, we will see a WARNING and the topic is created
// By default, the topic is created with 1 partition and 1 replication factor
// You cannot create replication factor higher than the number of broker. Then, localhost can only be created with replication 1
// local
$ kafka-topics --bootstrap-server localhost:9092 --create --topic first_topic
// remote
$ kafka-topics --command-config playground.config --bootstrap-server HOST_URL:9092 --create --topic first_topic --partitions 3 --replication-factor 2
$ kafka-topics --bootstrap-server localhost:9092 --list
$ kafka-topics --command-config playground.config --bootstrap-server HOST_URL:9092 --list
$ kafka-topics --bootstrap-server localhost:9092 --topic first_topic --describe
$ kafka-topics --command-config playground.config --bootstrap-server HOST_URL:9092 --topic first_topic --describe
$ kafka-topics --command-config playground.config --bootstrap-server HOST_URL:9092 --topic second_topic --deleteProducers
- Client applications that publish (write) events to Kafka
- The producers know in advance which particion to write to and which kafka broker
- Transform object to byte before send to kafka
- Kafka producers only write data to the current leader broker for a partition
- Retry: in case of failures it can retry (default 100ms). In this case, the message can be sent out of order
- Idempotent: even the message have been sent more than once, kafka will not have duplicate commits (messages)
- Acknowledgment (acks): number of replicas the message must be written before to be be considered successful
- acks=0: no response from kafka. In case of any error it is unknow and the data is lost
- acks=1: response from the leader regardless of replicas. If an ack is not received, the producer may retry the request. If the leader broker is not working and the replicas is not updated, we have a data loss
- acks=all: response from the leader only after the message is accepted by all in-sync replicas (ISR)
- Bast practice: acks=all and min.insync.replicas=2
// send local
$ kafka-console-producer --bootstrap-server localhost:9092 --topic first_topic
> Hello World local
// send remote without key
$ kafka-console-producer --producer.config playground.config --bootstrap-server HOST_URL:9092 --topic first_topic --producer-property acks=all
> Hello World Remote
// send with key
kafka-console-producer --producer.config playground.config --bootstrap-server HOST_URL:9092 --topic first_topic --property parse.key=true --property key.separator=:
>My key:my value
>name:MariaConsumers
- Subscribe to (read and process) events from Kafka
- Pull event data from one or more Kafka topics
- Consumers know which partition to read
- Consumers can read from one or more partitions
- Data is read in order from the same partition (from a lower offset to a higher offset - cannot read data backwards)
- The message order is not guaranteed when the data is read from more than one partition
- By default, Kafka consumers will only consume data that was produced after it first connected to Kafka
- Deserialization has to be done in the same format it was serialized in.
- In case switch a topic data format, the best practice is to create a new topic
- Consumers can commit offiset by the enable.auto.commit=true property every auto.commit.interval.ms (5 seconds by default) when .poll() is called.
$ kafka-console-consumer --bootstrap-server localhost:9092 --topic second_topic
$ kafka-console-consumer --consumer.config playground.config --bootstrap-server HOST_URL:9092 --topic second_topicConsumer groups
- Group of Consumers that performing the same "logical job"
- Identified by group.id
- Each consumer in a group is going to read from one partition
- Benefit: coordinate to split the work of reading from different partitions and ensure the load balancing (GroupCoordinator and a ConsumerCoordinator)
- Relation: 1 Topic assigned to 1 Consumer | 1 Consumer assigned to multiple Partition
- For more consumers than partitions then consumers will remain inactive
- Offiset help the remaining Kafka consumers know where to restart reading and processing messages in case of fail
- Always a new consumer is added to a group then consumer group rebalance happens
- When a consumer leaves a group its partitions are revoked and re-assigned
- Consumer Groups and Partition Rebalance: Eager Rebalance ; Cooperative Rebalance
Kafka message serializer
Kafka only acept and send bytes. it tranforms object in bytes. Use only value and key. The producer use this to serialize the data to send to kafka.
Zookeeper
- It tracks cluster state, membership, and leadership
- It determines which broker is the leader of a given partition and topic and perform leader elections
- Send notification to kafka in case of change
- It does not store consumer offsets with kafka
- It stores configurations for topics and permissions
Kafka KRaft
Created to overcome performance bottleneck with Zookeeper
The Schema Registry
It helps register data schemas in Apache Kafka and ensure that producers and consumers will be compatible with each other while evolving. It supports the Apache Avro, Protobuf and JSON-schema data formats.
Batch
- If producer try to send a lot of message in parallel (e.g max.in.flight.requests.per.connection=5) kafka is smart enought to start batching them
- It helps to increase throughput and maintaning low latency
- linger.ms: property to define how long to wait until send a batch
Example in Java
- Producer: send a message to the topic to your kafka playground [ProducerDemo]
- Consumer: retrieve a message from the topic in your kafka playground [ConsumerDemo]
Summary - which use
- From Source database to kafka: Kafca Connect Source
- Produce data directly to kafka: Kafka Producer
- Kafka to Kafka transformation: Kafka Streams/ KSQL
- From kafka to a database: Kafka Connect Sink
- To use direct the mesage: Kafka Consumer