JPA
Hello World!!!
In the last post, I talked to you about Java EE. We saw that Java EE have many related specifications. Now I will talk to you about one of them, Java Persistence API (JSR 338), introduced in Java EE 5. The code used here is at my GitHub.
Introduction
We can understand persistence in Java such as mapping and store object instances in a database using SQL. In other words, there are data transformations from one representation to another.
JPA is the standard API developed for the management of persistence and object/relational mapping (ORM). It simplifies the mapping Java objects to databases.
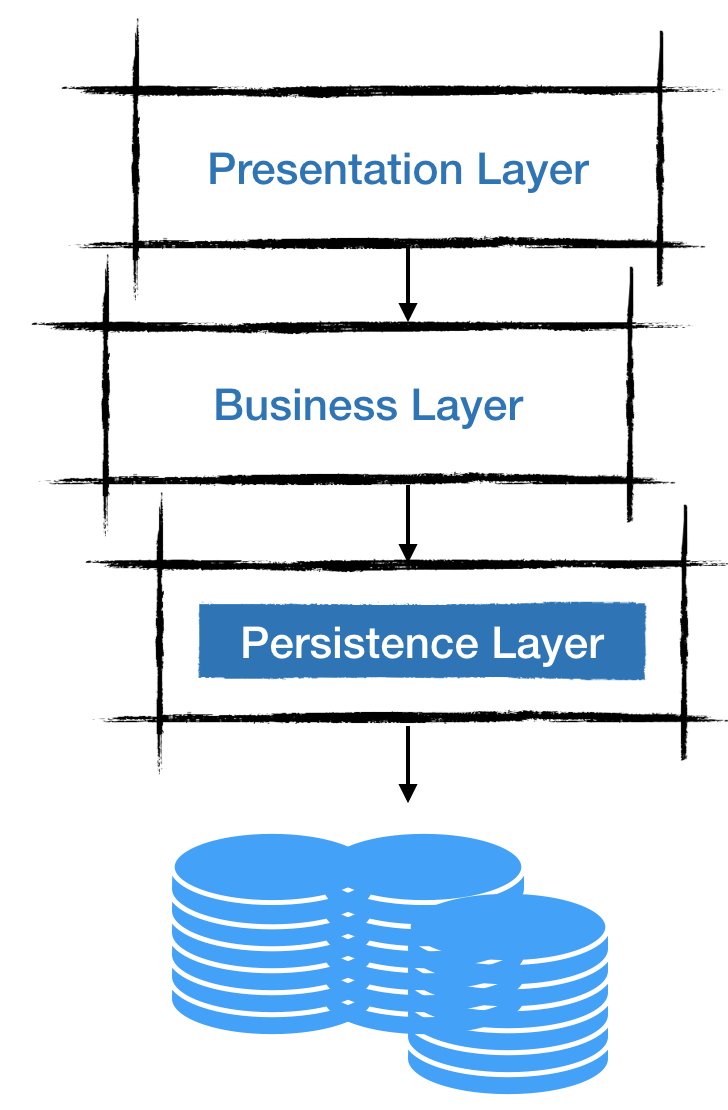
This API is usual in a persistence layer. In a generic way, each layer of a layered architecture is dependent only on the interface of the layer directly below it. A persistence layer is a group of classes and components responsible for manipulating data from one or more data stores (a persistent representation of the system state).
Any JPA provider has to support a minimum set of Java-to-SQL type conversions. SQL type names are ANSI-standard type names. JDBC provides a partial abstraction of vendor-specific data types. A provider translates from the ANSI-standard type to an appropriate vendor-specific type using the configured SQL dialect.
The JPA specification defines the following:
- A facility to specify the mapping of metadata
- APIs for performing basic CRUD operations on instances of persistent classes
- A language and APIs to specify queries that refer to classes and properties of classes (Java Persistence Query Language - JPQL)
- Dirty checking, association fetching, and other optimization functions
To add persistence dependency you should put this in your pom.xml:

Persistence Unit
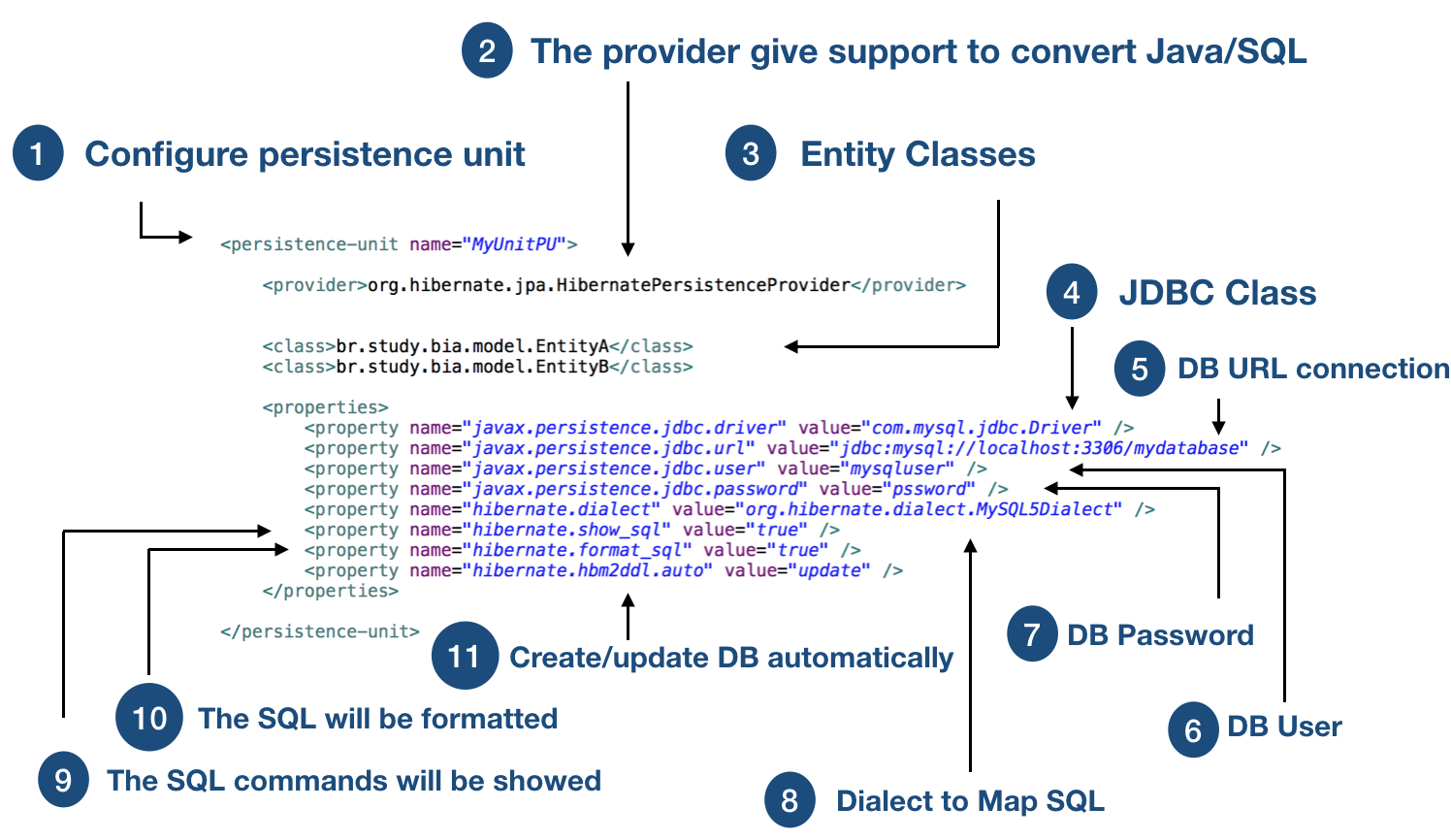
The persistence unit is the start point in JPA. With that, it’s possible to match the domain model class mapping with a database connection, for example. Every application has at least one persistence unit.
The standard configuration file is persistence.xml and it should be created inside a folder named META-INF.
Entity Manager
Entity manager factory and its entity managers have the control of the data. So, you need an EntityManagerFactory to access to your database. The EntityManagerFactory represents your persistence unit.
The modifications on objects managed by an EntityManager are in memory. At some point, they will be synchronized with the database. That synchronization happens with a JPA transaction created by EntityManager.

The @PersistenceUnit annotation is used to express a dependency on an entity manager factory and its associated persistence unit.
Persistence Context
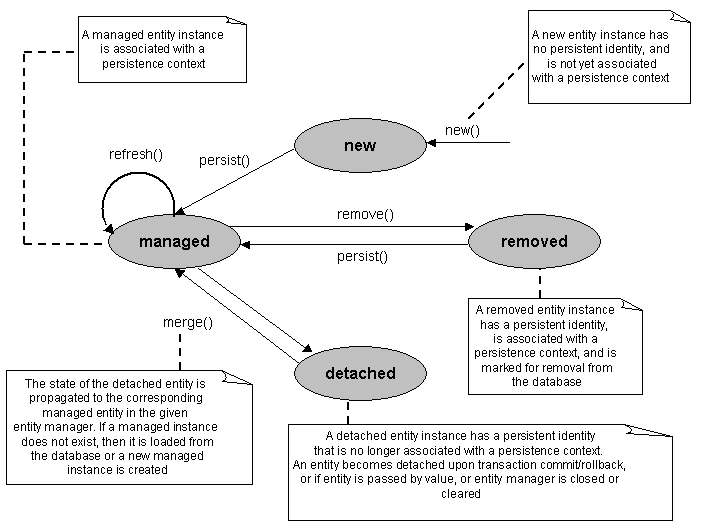
When an EntityManager is created then its persistence context is started. A persistence context is a set of entity instances in which for any persistent entity identity there is a unique entity instance.
The persistence context manages the entity instance and its lifecycle. Those entity classes are defined in the persistence unit.
The EntityManager interface defines the methods that are used to interact with the persistence context.

The @PersistenceContext annotation is used to express a dependency on a container-managed entity manager and its associated persistence context.
Entity Instance’s Life Cycle – Chapter 6. Java Persistence Entity Operations
Annotation
To the mapping, it’s possible to use annotations in Java code and externalized XML descriptor files. Whereas the annotations and the information are together, the XML descriptor is physically separated into a different file.
To map, for example, classes with tables or properties with columns, the ORM tools require metadata. Metadata is data about data.
Entity Class
The entity is the primary programming artifact necessary to be created to the application. It represents an object of your domain model.
Specification: The entity class must have at least a no-arg constructor. The entity class must not be final. If an entity instance is to be passed by value as a detached object (e.g., through a remote interface), the entity class must implement the Serializable interface.
The properties of a persistence class are persistent as well. To exclude these properties is necessary to map them as transient properties (@Transient).

The first important mapping to do in a persistence class is the Entity mapping. It can be done through the @Entity annotation or through the XML descriptor. The descriptor should be in the META-INF folder.

If you don’t use the attribute “name” in @Entity annotation, the entity name will use the class name. Using @Table you can map the table of the database.
Entity class has an @Id property, the database identity; it’s how JPA exposes database identity to the application.
The @GeneratedValue set an automatic generation mechanism of the values for the primary keys by the application. If this annotation is not used then the programmer is responsible for that.
The value-generation strategies can be chosen with the GenerationType enum:
- javax.persistence.GenerationType.AUTO
- javax.persistence.GenerationType.SEQUENCE
- javax.persistence.GenerationType.IDENTITY
- javax.persistence.GenerationType.TABLE
The @Id and @GeneratedValue annotations are used for database identity. The others properties can use, for example, @Basic or @Column. Using @Basic annotation, you can say if that property is optional. The @Column annotation can do the same thing but has a few other parameters.
To map a Date type column, you should use @Temporal annotation.
The enumeration type is mapped using the annotation @Enumerated where you can choose to persist the ORDINAL position or the STRING of the enum value as it is.

Other important mappings are images or large data.

Entity Relationship
Using JPA, you are able to map different kinds of relationships among entities. Their instances don’t have a dependent life cycle, but sometimes, you need more fine-grained control of how the relationship between two classes affects instance state.
The relationships can be uni or bidirectional.
For many-to-many bidirectional relationships, either side may be the owning side. The inverse side of a bidirectional relationship must refer to its owning side by use of the mappedBy element.
Associations that are specified as OneToOne or OneToMany support use of the orphanRemoval option. If an entity that is the target of the relationship is removed from the relationship, the remove operation will be applied to the entity being orphaned. The remove operation is applied at the time of the flush operation.
many-to-one : the simplest
 |
- The fetch parameter default value for Many-to-One annotations is EAGER. Using EAGER strategy, when a entity is loaded from database, their associated instances are loaded as well.
- The @JoinColumn annotation maps the foreign key column. The optional nullable parameter specifies if a value for the attribute is mandatory.
- It’s possible to make this a bidirectional association using the inverse association @OneToMany annotation in the dependent class.
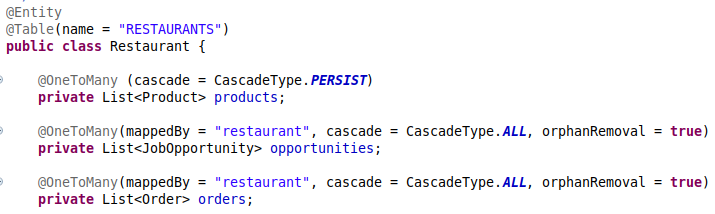
one-to-many
![]()
- It is a collection of entity references. This mapping makes possible the navigational access to data.
- In this case, you also have to refer to its owning side using the mappedBy parameter.
- The fetch parameter default value for One-to-Many annotations is LAZY. If you want complete objects you need set them with EAGER.
- The cascade parameter sets the strategy to control dependencies between associated entity classes in order to maintain the integrity of the instances.
- The orphanRemoval is another parameter that allows to remove an entity permanently when it’s removed from a collection. But you need to take care about that parameter because you can have an inconsistency in memory.
one-to-one,

- In the bidirectional relationships, the owning side corresponds to the side that contains the corresponding foreign key.
- Rows in two tables related by a primary key association share the same primary key values.
many-to-many

- For many-to-many bidirectional relationships, one of the entities must be the owning side
- Usually, a Many-to-Many mapping is implemented using a Set Java type. That structure does not contain duplicate elements.
- You can use the @JoinTable annotation in which you can specify the name of the intermediate table.
- You may represent a many-to-many association as two many-to-one associations.
Implementations
To use JPA you need a provider that implements the interfaces. The most popular are EclipseLink and Hibernate.
The EclipseLink is a complete JPA’s reference implementation. Then, it is a reference to every provider.
To use EclipseLink in your project you can add this to your pom.xml:
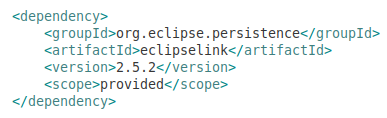
To use Hibernate in your project you can add this to your pom.xml:
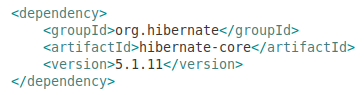
There is a difference about the class declaration. Using Hibernate it’s possible to map using @Entity only, but using EclipseLink you should declare classes in persistence.xml.
There is a work that compares the performance of the EclipseLink and Hibernate in different scenarios. It shows the Hibernate with better results.
- Hibernate is more efficient than EclipseLink in persistence, query, update and remove operations.
- EclipseLink is more efficient than Hibernate on retrieval operations.
You can see some interesting proprietary features here.
Summary
Conclusion
JPA is a great option to map classes and tables and there are different implementations to make the development tasks easier. The choice depends on the necessities of the project.
JPA is a extense subject. Here it’s just the start. Next time, I will dive in a little more about it.
All the code can be seen here.
See you!!!
References
- My github
- Chapter 6. Java Persistence Entity Operations
- Java Persistence with Hibernate
- Pro JPA 2
- Hibernate - Many-to-Many Mappings
- Chapter 5. Basic O/R Mapping
- https://www.devmedia.com.br/introducao-ao-eclipselink/29131
- http://www.vogella.com/tutorials/JavaPersistenceAPI/article.html
- http://www.jpab.org/Hibernate/MySQL/server/EclipseLink/MySQL/server.html
- http://blog.caelum.com.br/jpa-hibernate-ou-eclipselink/